Pessoal, a Microsoft disponibilizou os links para Download das versões Preview do Visual Studio 2013 e também, do SQL Server 2014 CTP1.
Para baixá-los, seguem os link:
Visual Studio 2013 Preview
http://www.microsoft.com/visualstudio/eng/2013-downloads
SQL Server 2014 CTP1
http://technet.microsoft.com/pt-BR/evalcenter/dn205290.aspx
Bom, logo mais farei um artigo descrevendo as novidades do SQL Server 2014 CTP1.
Bons estudos.
sexta-feira, 28 de junho de 2013
quinta-feira, 2 de maio de 2013
Atachando um arquivo de Banco de dados MDF sem o Arquivo de Log no SQL Server
Olá a todos.
Após um pequeno tempo sem escrever no Blog, trago mais um artigo com
uma necessidade que tive e então, resolvi compartilhar.
Recentemente necessite anexar um Banco de dados no Servidor SQL Server
que trabalho, porém, somente foi entregue para mim o arquivo MDF e sem o
arquivo de LOG para que eu pudesse atachá-lo junto.
Para enfatizar este artigo, usarei como exemplo o arquivo MDF sem os
LOGs da base de Dados AdventureWorksDW2012, que por sua vez pode ser baixado no
seguinte endereço:
-
AdventureWorksDW2012:
http://msftdbprodsamples.codeplex.com/downloads/get/165405
Normalmente faríamos este processo utilizando as seguintes sequências
de telas:

Figura 1 – Selecionando a Opção de Attach no Banco de Dados

Figura 2 – Selecionando o arquivo MDF do Banco de dados que iremos
atachar.
Desta forma, ao selecionarmos nosso banco de dados, conforme veremos na
Figura 3 abaixo, o mesmo somente terá o arquivo MDF sendo informado, onde, para
o Arquivo de Log, aparece uma mensagem ao lado direito da indicação do caminho
do arquivo, informando que o mesmo não fora localizado.
Se tivéssemos o arquivo LOG disponível no computador/servidor, bastaria
somente informarmos seu local de origem.

Figura 3 – Apresentando o arquivo MDF sem o Log informado.
Para resolvermos este problema, poderemos agir de duas formas, sendo a
primeira:
- Removendo via Tela do SSMS a informação do arquivo de Log,
selecionando o mesmo na tela que estamos utilizando para atachar o arquivo,
conforme a Figura 4 demostra.

Figura 4 – Removendo o arquivo de Log pelo SSMS
- Executando uma query com a Procedure sp_attach_single_file_db, que
espera receber dois parâmetros:
@dbname nvarchar(128): Nome do Banco de Dados
@physname nvarchar(260): Caminho de origem do arquivo MDF do Banco de
Dados
No final, a query será interpretada da seguinte forma:
EXEC
sp_attach_single_file_db
@dbname=’AdventureWorksDW2012′,@physname=’D:\Software\SQL
Server\MSSQL11.SQLBI01\MSSQL\DATA\AdventureWorksDW2012_Data.mdf’
GO
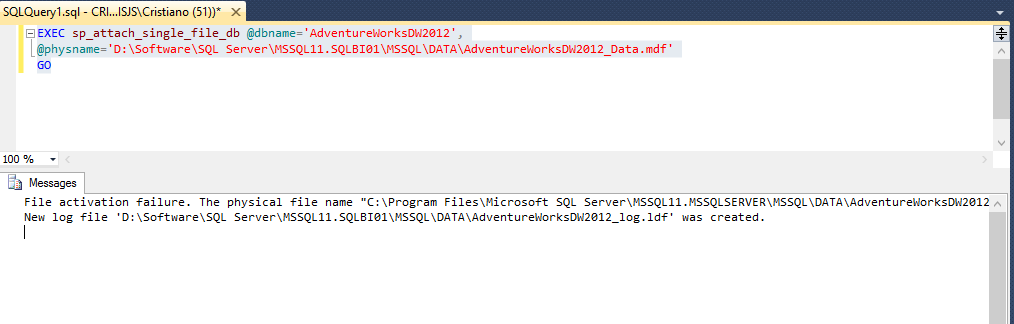
Figura 5 – Executando a query que irá atachar o banco de Dados
AdventureWorksDW
Após, o banco de dados será criado e já estará disponível no SSMS,
conforme Figura 6 abaixo.
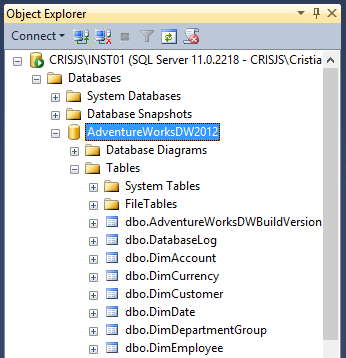
Figura 6 – Banco de Dados criado e disponível no SQL Server
Só como Observação, este bancp de Dados do AdventureWorksDW é um modelo
utilizado nos estudos do ambiente de BI da Microsoft, estando também disponível
na versão do SQL Server 2008 R2.
Bons estudos.
Microsoft lança o Service Pack 1 do SQL Server 2012
Recentemente a Microsoft lançou o Service Pack 1 do SQL Server 2012.
Esta versão contém correções para problemas que foram relatados através de
comentários dos clientes.
Como novidade, destaques para acessos a BI Self-service, através de
ferramentas como o Excel 2013, utilizando tecnologias “in-memory”.
Seguem o link para que a versão 64 Bits do Service Pack possa ser
baixada:
Para a versão 32 Bits do SQL Server, podemos baixar acessando o link:
As atualizações estão disponíveis para todas as versões do SQL Server
2012.
Até a próxima.
Usando C# no Microsoft Integration Services
Com o lançamento do Microsoft SQL Server 2005, passamos a conhecer uma
nova ferramenta, que veio com o propósito de incluir a Microsoft como um dos
grandes players do Mercado, no que diz respeito ao universo de BI (Business
Inteligence). Desta forma, passamos a falar do Microsoft SQL Server Integration
Services (também conhecido como SSIS).
Desde 2005 para cá, particularmente eu posso falar que a Ferramenta
amadureceu o suficiente para se destacar frente a outras demais ferramentas de
ETL (Extract, Transform and Load – Extrair, Transformar e Carregar).
Este processo diz respeito a unificar informações de Bases de Dados
transacionais, que são informações que estão em nossas bases de dados e que são
gravados pelos Sistemas desenvolvidos em .NET, Java, Delphi e etc., e enviá-las
para uma base de dados histórica, sendo esta conhecida como Data Warehouse
(DW). Esta base é modelada de uma forma diferente da qual conhecemos, sendo que
as Bases de Dados Transacionais pregam a ideia de Normalização dos Dados e a
base de Dados do Data Warehouse (DW), trabalha com a ideia de “desnormalização”
destes dados.
Em siglas, esta diferença pode ser considerada ao falarmos dos
ambientes OLTP (Online Transaction Processing) e OLAP (Online Analytical
Processing).
Mas o intuito deste artigo não é falar especificamente sobre a
Arquitetura que envolve um processo de BI (onde a Microsoft possui uma suíte
completa de ferramentas) e sim, apresentar como o Microsoft SSIS (SQL Server
Integration Services) se encaixa dentro desta arquitetura.
Estou utilizando a Versão do Microsoft SQL Server 2012, que quando
instalado cria um Shell do Microsoft Visual Studio na versão 2010, que
possibilitará trabalharmos com projetos do Integration Services.
Aqui no micro que estou preparando este artigo, possuo a versão do
Microsoft Visual Studio 2010 completo.

Figura 1 –Template de Projetos do Integration Services no Shell do
Visual Studio 2010
Porém, mesmo utilizando o Visual Studio e tendo o Microsoft SQL Server
(versões 2005, 2008/2008 R2 e 2012) instalados no micro de Desenvolvimento,
muitos dos colegas que trabalham com estas plataformas não utilizam as
ferramentas instaladas. Mesmo os colegas que estão iniciando no universo de BI
com a plataforma da Microsoft, se perguntam como fazer atividades como:
Utilizar IF, ELSE no Integration Services.

Figura 2 – Um Projeto do Integration Services aberto no Visual Studio
2010.
Bom, vamos iniciar nosso exemplo deste artigo.
Antes de mais nada, aos colegas que não conhecem o SSIS, prepararei
logo mais um artigo específico para apresentar outros detalhes da Ferramenta.
Com o Visual Studio aberto, iniciaremos nosso estudo criando um projeto
do Integration Services, dando para o mesmo o nome de: Usando DOT_NET_SSIS.
No SQL Server 2012, temos o Banco de Dados AdventureWorks e a tabela
Product, que será utilizada para nosso artigo.
Na tela principal temos Abas, onde cada uma delas possui uma
Funcionalidade Específica, de acordo com cada Aba selecionada. A Figura 3
apresenta com detalhe a Aba inicial Control Flow com seus respectivos Itens da
ToolBox.

Figura 3 – Aba Control Flow do Visual Studio com seus respectivos Itens
da ToolBox.
Bom, a ideia do artigo é apresentar a utilização do Item Execute SQL
Task para selecionarmos alguns produtos da Tabela Product do Banco
AdventureWorks, no qual trabalharemos com produtos que possuam a Lista de
Preços de valores entre 50 e 100 (Dólares, Reais ou qualquer outra, como
quiserem).
Porém, para pegarmos estes registros da Tabela de Produtos, temos
primeiro que nos conectar no Banco e após, fazermos este Select.
O Item Execute SQL Task ao ser anexado nos fornece a opção de
conectarmos ao Banco de dados do SQL Server, conforme apresentado na Figura 6.

Figura 4 – Adicionando o Execute SQL Task para executar o Script no
Banco de Dados.
Para nosso exemplo, criei uma conexão no qual posso utilizar em todo o
Projeto, ou seja, uma conexão Global. A Figura 7 abaixo demostra o lugar onde a
mesma fora criada.

Figura 5 – Criando uma conexão Global para o projeto
Em sequência, criei o seguinte Script abaixo para realizar tal tarefa,
onde este Script retorna todos os registros dentro da Tabela, conforme a Figura
8 apresenta.
SELECT * FROM Production.Product

Figura 6 – Retorno da Execução da Query apresentada no Script, dentro
do SQL Server 2012.
A consulta retorna 504 registros onde a ideia do artigo será
exportarmos Produtos com os valores menores que 100 para um arquivo TXT
específico e os Produtos de valores maiores para um segundo arquivo TXT.
Para a consulta que retorna Produtos com valores de Lista de preço
menores que 100, gravaremos no arquivo ProdutoMenor100.txt, onde os Produtos
com Lista de preço maior que 100, serão gravados no arquivo ProdutoMaior100.txt
(por conveniência particular, vou gravar ambos os arquivos no Disco C:\).
Bom, vamos voltando ao nosso exemplo.
No Visual Studio, após incluirmos o Item Execute SQL Task, incluiremos
também mais um Item: O Script Task. Este item nos possibilita trabalharmos com
Código .NET (seja C# ou VB .NET), para podermos incluir em nossa rotina, algum
fluxo desenvolvido por uma destas linguagens. Imaginem vocês que para
validarmos algum processo de nossa regra de negócio, necessitaríamos, por
exemplo, consumir uma DLL desenvolvida em .NET ou um Método em Webservice ou
WCF. Com este item, poderemos adicionar tal funcionalidade.
Com isso, arraste o Item Script Task, que nesta versão do Integration
Services dentro do Shell do Visual Studio, está localizado na seguinte posição:

Figura 7 – Localizando o Script Task dentro da SSIS Toolbox
Após, de o nome para o mesmo de: ST_IF_Else, onde em seguida, clique
com o Botão direto do Mouse sobre ele e selecione a Opção EDIT. Será aberta uma
Tela, semelhante a da Figura 10, abaixo.

Figura 8 – Editando o componente Script Task
Conforme estão vendo na Figura 10 acima, temos a opção de selecionarmos
qual linguagem estaremos trabalhando. Neste exemplo, estou utilizando a
Linguagem C#, porém, poderíamos configurar a Linguagem VB .Net sem problemas,
alterando nas Propriedades do Item qual Linguagem utilizaremos, conforme é
apresentado na Fiura 12, abaixo.

Figura 9 – Configurando qual Linguagem utilizar como Script
A opção EntryPoint, descreve qual o método de Entrada que estaremos
utilizando no Script. Podemos deixar em branco, ou então, descrever qual método
iremos utilizar. Por padrão, eu deixei o método Main.
Após, temos duas opções que serviram tanto descrever quais as variáveis
serão utilizadas para somente leitura e quais as variáveis serão utilizadas
para somente escrita.
Bom, como estamos trabalhando com um Bloco de script que, deveremos
interagir entre o SSIS e a tal linguagem de alguma forma. Para isso, poderemos
utilizar variáveis para tanto levar um conteúdo para as rotinas do .NET, quanto
trazer este retorno de processamento. Desta forma, poderemos interagir sem
problemas com fluxos externos deste ambiente. Desta forma, clique com o botão
direito do mouse sobre a área de desenvolvimento do Visual Studio e selecione a
opção Variables.

Figura 10 – Selecionando as opções Variables na Tela do Visual Studio
Após, percebam que o Visual Studio abrirá uma tela, onde poderemos
inserir a quantidade de variáveis que desejarmos em nosso processo. No nosso
exemplo, criaremos 3 (três) variáveis, onde ainda poderemos escolher qual o
Data Type estaremos utilizando e seu Valor inicial (poderemos ainda aplicar
expressões para estas variáveis, mas não é o caso). Percebam também que a
variável criadas trabalha sobre o escopo da Package, pois como não alterei o
nome do meu Pacote do Integration Services, acabou sendo adotado o nome
principal do arquivo da Package.dtsx, visível na Aba Solution Explorer do
Visual Studio. Perceba também que o Data Type da Variável é do tipo Object
(mais para frente o mesmo será convertido para DataSet e será utilizado no
Script).

Figura 11 – Criando as variáveis que serão utilizadas no Script Task
Após criarmos a variáveL, teremos que selecioná-la nas Opções:
ReadOnlyVariables. Neste caso não utilizaremos a opção ReadWriteVariables, pois
realmente só iremos ler a variável
que será encaminhada do retorno do Item o Execute T-SQL Statement. Para
isso, deveremos seleciona-las na opção do Editor do Script Task, conforme
apresentado nas Figuras 14 e 15.

Figura 12 – Selecionando as variáveis que serão utilizadas no Script
Task
Bom, não vou detalhar o que o Script em si está fazendo, porém, não
posso deixar de explicar sua funcionalidade. Para os colegas que estão
acostumados com o ambiente .NET na linguagem C# e/ou VB .NET, não sentirão
dificuldades, pois, utilizaremos tais linguagens para codificar algum fluxo,
onde poderia ser uma regra de negócio, ou uma chamada a uma DLL que tenha
métodos de negócio encapsulados.
Perceba na Figura 15 a Aba de Código do Visual Studio aberta e com a
descrição do Método Main, que receberá a variável ResultSet (fique a vontade
para mudar este nome).

Figura 13 – Método Main do Script C#
Este método irá pegar a variável ResultSet (Figura 13) e a converte
para um DataTable. Logo após, iremos varrer este DataTable em um FOR LOOP e
para cada linha, verificaremos os campos ProductID, Name e ListPrice. Se o
campo ListPrice for maior que 50 e menor que 75, chamaremos o método
GeraArquivo_Preco50_75, que simplesmente irá criar um arquivo chamado
Arq50_75.txt no Diretório C:\, se utilizando do Namespace
System.IO.StreamWriter, inserindo via WriteLine os campos ProductID,
ListaPreco, NomeProduto (traduzi o nome dos campos), concatenados por ponto e
vírgula (“;”).

Figura 14 – Método que Gera o arquivo com os dados do Produto, Nome do
Produto e Preço entre 50 e 75.
Da mesma forma, caso o campo ListPrice for maior que 75 e menor que
100, chamaremos o Método GeraArquivoPreco75_100, que da mesma forma receberá os
campos ProductID, Name e ListPrice e gerará um arquivo chamado Arq75_100.txt no
C:\.

Figura 15 – Método que Gera o arquivo com os dados do Produto, Nome do
Produto e Preço entre 75 e 100.
Na Figura 18 abaixo, veremos os dois arquivos (na mesma janela), com
seus respectivos registros, sendo que para o arquivo com Preços entre 50 e 75 é
maior do que o arquivo de Preços entre 50 e 75.

Figura 16 – Mostrando os arquivos e seus respetivos conteúdos
Bom, vale lembrar que você poderá mudar o caminho do arquivo, ou até
mesmo o nome do próprio arquivo, ou até quem sabe, programar outro Código em C#
ou .NET, pois a intensão do artigo foi somente indicar a possibilidade de
integrar o SSIS com as linguagens C# e VB .NET, utilizando para isso o Visual
Studio 2010.
Bom estudo.
Diferenças entre SEQUENCES x IDENTITY no Microsoft SQL Server 2012
Bom, a pedido dos colegas que viram o Artigo Utilizando Sequences noMicrosoft SQL Server 2012, resolvi criar um novo artigo que faz uma comparação
entre o uso de SEQUENCE x IDENTITY no Microsoft SQL Server 2012.
Uma das diferenças entre SEQUENCE e IDENTITY está no fato de que as
SEQUENCES são acionadas sempre quando forem necessárias, sem dependência de
tabelas e campos no banco, onde pode ser chamada diretamente por aplicativos.
Outra diferença está que nas SEQUENCES, nós podemos obter o novo valor
antes de usá-lo em um comando, diferente do IDENTITY, onde não podemos obter um
novo valor. Além disso, com o IDENTITY não podemos gerar novos valores em uma
instrução UPDATE, enquanto que com SEQUENCE, já podemos.
Com SEQUENCES, podemos definir valores máximos e mínimos, além de
termos a possibilidade de informar que a mesma irá trabalhar de forma cíclica e
com cache, além de podemos obter mais valores em sequencia de um só vez,
utilizando para isso a procedure SP_SEQUENCE_GET_RANGE, onde então é permitido
atribuirmos os valores individuais para aumentar então o desempenho no uso da
SEQUENCE.
Uma das grandes utilidades em IDENTITY que vejo ser muito valiosa está
no fato de podermos trabalhar com o mesmo na utilização de TRANSAÇÕES de
INSERT, pois, só iremos gerar um próximo valor a partir do momento que o
comando for executado, ou seja, que a transação for aceita, ao contrário de uma
SEQUENCE, que uma vez chamado seu próximo valor, mesmo que ocorra um erro de
transação, o valor é alterado.
Abaixo, tenho um exemplo d0 Script feito e a Imagem 1 apresentando este
Script que possa nos dar uma ideia do que estou falando. Este Script irá criar
duas tabelas com a mesma estrutura, sendo que o que as diferenciará será, claro
que o nome, e seus campos de chave primária.
CREATE DATABASE
Artigos
GO
USE Artigos
GO
CREATE TABLE
TBL_UsoIDENTITY
(
ID_Uso INT
IDENTITY(1,1),
DSC_Desc NVARCHAR(30)
NOT NULL,
CONSTRAINT
ID_Uso_IDENTITY_PK PRIMARY KEY (ID_Uso)
)
GO
CREATE TABLE
TBL_UsoSEQUENCE
(
ID_Uso INT,
DSC_Desc NVARCHAR(30)
NOT NULL,
CONSTRAINT
ID_Uso_SEQUENCE_PK PRIMARY KEY (ID_Uso)
)
GO

Imagem 1 – Script que criará as tabelas de exemplo
Na Imagem 1 acima, percebem que na linha 9, do campo ID_Uso da tabela
TBL_UsoIDENTITY, criamos o campo descrevendo que o mesmo será do tipo Inteiro e
em seguida, terá o IDENTITY. Esta é a forma que já conhecíamos nas versões
anteriores do SQL Server.
Contudo, a partir da linha 15 do Script na Imagem 1, verificamos a
criação da tabela TBL_UsoSEQUENCE, que traz o mesmo campo ID_Uso, seguido do
seu tipo, porém, sem nenhuma declaração mais.
Percebam também que ambos os campos são PRIMARY KEY, cada uma com seu
respectivo nome.
Bom, conforme eu tinha falado no artigo Utilizando SEQUENCES no SQLServer 2012, os objetos SEQUENCES não estão vinculados a tabela. Este vinculo
irá ocorrer, por exemplo, se utilizando de PROCEDURES.
Vamos ver a diferença na prática. Para isso, irei criar mais ScriptS
para dar um exemplo do que estou falando.
Vou criar a SEQUENCE dbo.SEQ_Artigo, com o Script abaixo:
USE [Artigos]
GO
CREATE SEQUENCE
dbo.SEQ_Artigo
START WITH 1
INCREMENT BY 1
NO CACHE
NO CYCLE
GO

Imagem 2 – Script gerado para criar uma SEQUENCE
Com a SEQUENCE criada, irei agora fazer um novo Script para criar duas
PROCEDURES, cada uma para trabalhar com as tabelas criadas anteriormente.
Inclusive, segue o Script para criação da primeira Procedure.
USE [Artigos]
GO
CREATE PROCEDURE
[dbo].[PRC_USANDO_IDENTITY]
@DSC_Desc NVARCHAR(30)
AS
DECLARE @ValorDIVIDE
NUMERIC(3);
BEGIN TRANSACTION
BEGIN TRY
INSERT INTO
dbo.TBL_UsoIDENTITY
VALUES
(
@DSC_Desc
);
SET @ValorDIVIDE = 10
/ 0;
COMMIT TRAN
END TRY
BEGIN CATCH
ROLLBACK TRANSACTION
SELECT
ERROR_NUMBER() AS
ErrorNumber
,ERROR_MESSAGE() AS ErrorMessage;
END CATCH

Imagem 3 – Criando a Procedure vinculada a Tabela TBL_UsoIDENTITY
Vamos agora explicar o que está ocorrendo dentro desta PROCEDURE:
Se vocês olharem bem, eu tenho a declaração de uma BEGIN TRANSACTION,
sendo que possuo dentro desta transação um comando de INSERT na tabela
TBL_UsoIDENTITY. Não estou passando nenhuma valor para o campo ID_Uso, pois,
pelo fato dele ser IDENTITY, automaticamente irá gerar/incluir os campos .
Antes porém, além da declaração do parâmetro de entrada, tenho também a
declaração de uma variável chamada @ValorDIVIDE do tipo NUMERIC. Após realizar
o INSERT, tenho esta mesma variável setada com uma operação de DIVISÃO, que
conforme verão, será feita pelo número 10 / 0. Contudo, sabemos que não existe
divisão por zero, ocasionando um erro dentro da PROCEDURE e um ROLLBACK da
transação.
Resumindo: Este comando de INSERT não será efetivado dentro da Tabela.
Agora, vou criar uma Procedure que irá ser vinculada a Tabela
TBL_UsoSEQUENCE e que irá tentar INSERIR informações dentro desta tabela. Para
isso, segue mais um Script:
USE [Artigos]
GO
CREATE PROCEDURE [dbo].[PRC_USANDO_SEQUENCE]
@DSC_Desc NVARCHAR(30)
AS
DECLARE @ValorDIVIDE
NUMERIC(3);
BEGIN TRANSACTION
BEGIN TRY
INSERT INTO
dbo.TBL_UsoSEQUENCE (ID_Uso, DSC_Desc)
VALUES
(
NEXT VALUE FOR
dbo.SEQ_ARTIGO,
@DSC_Desc
);
SET @ValorDIVIDE = 10
/ 0;
COMMIT TRANSACTION
END TRY
BEGIN CATCH
ROLLBACK TRANSACTION
SELECT
ERROR_NUMBER() AS
ErrorNumber
,ERROR_MESSAGE() AS
ErrorMessage;
END CATCH
GO

Imagem 4 – Criando a Procedure vinculada a Tabela TBL_UsoSEQUENCE
Da mesma forma, vamos explicar esta PROCEDURE:
Se vocês analisarem o Script na Imagem 4, verão que eu estou utilizando
uma variável chamada @ValorSEQUENCE e atribuindo a ela o resultado do comando
NEXT VALUE FOR dbo.SEQ_ARTIGO (que é a SEQUENCE criada anteriormente),
indicando assim para PROCEDURE buscar o próximo valor de sequencia da SEQUENCE.
Este valor, será inserido dentro do campo ID_Uso, que pelo fato de não ser mais
IDENTITY, necessita ser descrito no comando, e da mesma forma, incluo a variável
@ValorDIVIDE e tento fazer uma divisão por ZERO e como não existe divisão por
zero, apresenta um erro e a transação sofre um ROLLBACK.
Contudo, o valor da SEQUENCE foi alterado, não sendo mais o valor 1
iniciado no momento que a criamos.
Mas, vamos ver isso na prática. Execute os Scripts abaixo:
EXEC [dbo].[PRC_USANDO_IDENTITY] ‘Teste de IDENTITY’
GO
EXEC [dbo].[PRC_USANDO_SEQUENCE] ‘Teste de SEQUENCE’
GO
Percebam o erro da informação de Divisão por zero sendo retornado,
pois, tratamos esse erro com um TRY CATCH.
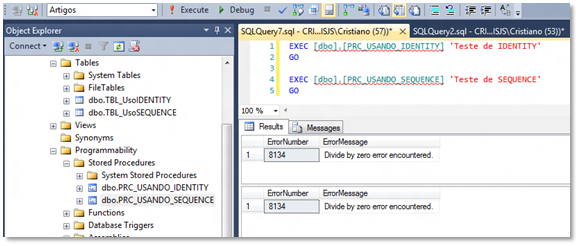
Imagem 5 – Executando as Procedures
O Conteúdo de ambas as tabelas não foi aferido, pelo fato de ser
executado um ROLLBACK. Porém, a SEQUENCE utilizada pela PROCEDURE
PRC_USANDO_SEQUENCE não estará mais com o seu valor inicial igual a 1.
Para confirmar isso, execute o Script abaixo a veja o resultado
semelhante ao da Imagem 6:
SELECT NAME,
CURRENT_VALUE FROM SYS.SEQUENCES
GO
SELECT
IDENT_CURRENT(‘dbo.TBL_UsoIDENTITY’)
GO
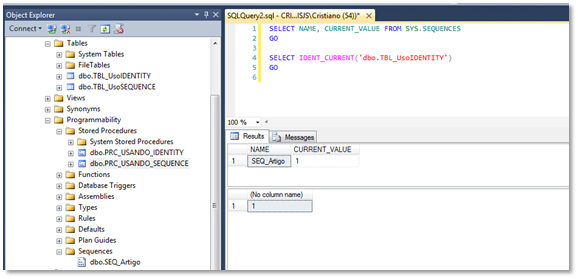
Imagem 6 – Verificando o valor atual da SEQUENCE e IDENTITY utilizados
no exemplo
Com isso, percebemos que para vermos o valor de uma SEQUENCE devemos
executar um SELECT na VIEW chamada SYS.SEQUENCES, sendo que temos um objeto
totalmente apartado de uma Tabela. No caso do IDENTITY, para verificarmos seu
valor, executamos um outro SELECT, porém, utilizando a função IDENTITY_CURRENT
e passando a tabela que desejamos consultar o último IDENTITY.
Entrentanto, se executarmos o Script abaixo, verificaremos que a
possibilidade de inserir valores para a SEQUENCE mesmo fora de uma PROCEDURE,
conforme é mostrado na Imagem 7, abaixo:
SELECT NEXT VALUE FOR
dbo.SEQ_ARTIGO;
GO

Imagem 7 – Atribuindo um valor para a SEQUENCE fora de uma PROCEDURE
Enfim, em alguns casos é interessante se utilizar IDENTITY e em outros,
SEQUENCE. O ideal é analisarmos nossa estrutura de tabelas e informações para
vermos se realmente queremos armazenar as informações com Autonumeração gerada
pelo IDENTITY ou pelo controle de Numeração de uma SEQUENCE.
Bons estudos.
Assinar:
Postagens (Atom)